Overview
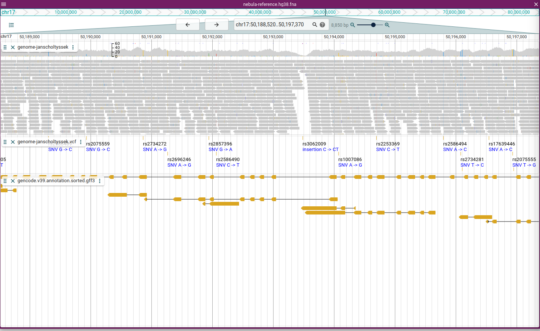
I got my whole genome sequenced by Nebula Genomics.
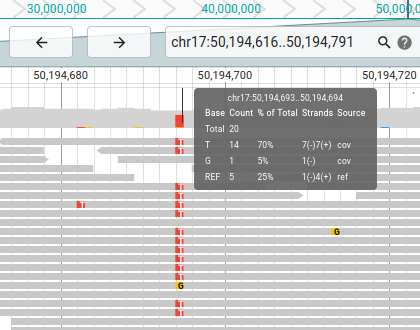
My motivation was to get an interesting data set with raw genome sequencing data. Our genome is several billion bases long (the G, A, C, T) but is sequenced a few hundred bases at a time. These small pieces (called “reads”) then need to be assembled like a Sudoku to get the whole genome. Using the raw data from my own genome I can try some of the algorithms for this and develop my own. At the same time I learn more about my genes and mutations and get to know techniques to differentiate normal mutations from potentially harmful ones. This is an important tool when selecting therapy options for cancer patients.
Some of my code, including code for reading CRAM files in C# is linked in the Project URL.
Services